뉴스 크롤링 데이터 기반 챗폿(ex. Perplexity)

방대한 뉴스 데이터를 실시간으로 수집하여, 신뢰할 수 있는 출처와 함께 답변을 제공하는 지능형 뉴스 AI 검색 엔진
🧱 시스템 아키텍처 상세 설계 (Data Pipeline)
1. Data Ingestion Phase (URL 수집 및 메시징)
- Target Scraper: 120개 주요 매체사의 500개 이상 카테고리를 실시간 모니터링합니다. 각 사이트의 계층 구조를 분석하여 최신 기사 URL 리스트를 정밀하게 추출합니다.
- Message Broker (Kafka): 수집된 수천 건의 URL을 Kafka Topic으로 발행(Produce)합니다. **생산자와 소비자 계층을 완전히 분리(Decoupling)**하여, 특정 매체사의 응답 지연이 전체 시스템의 병목으로 이어지는 것을 방지하고 가용성을 극대화했습니다.
2. Real-time Crawling Phase (분산 크롤링 및 차단 회피)
- Scalable Consumers (Playwright): 다수의 Playwright 컨슈머가 Kafka 메시지를 구독하여 본문 수집을 수행합니다. JS 렌더링이 필요한 동적 페이지를 완벽히 캡처하며, 헤드리스 브라우저 컨트롤로 수집 안정성을 확보했습니다.
- Anti-Blocking & Rate Limiting:
- 도메인별 속도 제어: 120개 매체사의 각기 다른 보안 정책에 대응하여, 도메인별 크롤링 빈도를 동적으로 조절하는 Rate Limiting 로직을 구현했습니다.
- 차단 회피 설계: User-Agent 로테이션 및 요청 헤더 최적화를 통해 사이트 차단 리스크를 최소화했습니다.
- Fault Tolerance (누락 방지): 크롤링 실패 시 재시도(Retry) 메커니즘과 에러 로그 추적을 통해 대량 데이터 처리 중 발생할 수 있는 데이터 누락 이슈를 원천 차단했습니다.
3. Storage & Indexing Phase (RAG 최적화 및 저장)
- Data Labeling & Embedding: 수집된 뉴스 본문을 정제하고 발행일, 카테고리 등 메타데이터를 라벨링합니다. 이후 텍스트를 고차원 벡터로 변환하여 문맥적 의미를 추출합니다.
- Quantized Hybrid Search (Elasticsearch):
- 양자화(Quantization): 임베딩 값을 양자화하여 저장함으로써 검색 엔진의 메모리 점유율을 약 50% 이상 절감하고 검색 속도를 비약적으로 향상시켰습니다.
- Hybrid Indexing: **BM25(키워드 검색)**와 **Vector(의미 검색)**를 결합하여, 고유 명사가 많은 뉴스 데이터의 특성에 최적화된 하이브리드 검색 기반을 마련했습니다.
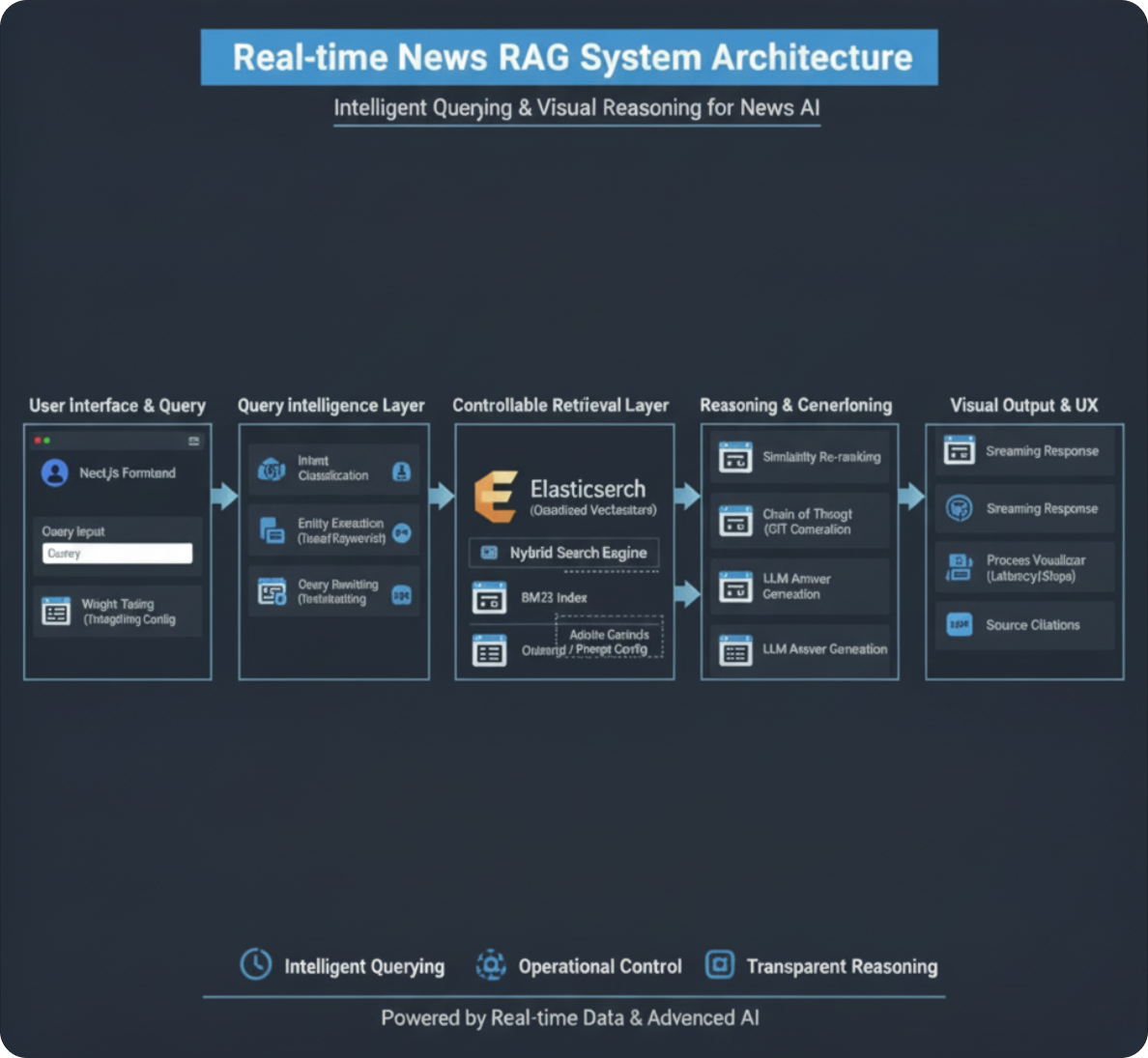
4. 지능형 RAG 파이프라인 아키텍처 (Query & Reasoning Focus)
이 아키텍처는 사용자의 질문이 들어왔을 때 바로 검색하는 것이 아니라, **'의도 파악'**과 '최적화' 과정을 거치는 것이 핵심입니다.
Step 1: Adaptive Query Analysis (질문 분석 및 분류)
- 분류 (Classification): LLM을 활용해 질문을 세 가지 유형으로 분류합니다.
- 정보성(Informative): 검색이 필요한 질문.
- 시제(Temporal): "어제", "작년" 등 특정 시점이 중요한 질문 (Elasticsearch 필터링 조건 생성).
- 일상 대화(Chitchat): 검색 없이 즉시 답변하여 리소스 절약.
- 구체화 (Query Expansion/Rewriting): 모호한 질문을 BM25용 키워드와 벡터 검색용 문맥으로 재구성합니다.
Step 2: Controllable Search (운영 최적화)
- 프롬프트 엔지니어링 & 가드레일: 특정 도메인이나 운영 방침에 따라 답변의 톤이나 가중치를 조정할 수 있도록 시스템 프롬프트를 모듈화했습니다.
- Hybrid Scoring: BM25의 텍스트 매칭과 임베딩의 의미 매칭 결과에 운영자가 설정한 가중치를 부여하여 아웃풋의 우선순위를 조정합니다